Crawling Web Archives (Experimental)¶
Attention
Crawling can be very hard on a web archive. Please read Caching and being nice to web archives section first.
Sometimes seed mementos are not enough and we want to discover the deep mementos within a collection. The identify action accepts an optional (and experimental) --crawl-depth parameter with a number specifying the depth to crawl. If this is specified, then Hypercane will invoke Scrapy to crawl the input to the given depth and then employ the Memento Protocol to discover the desired output. We thank Mohamed Aturban for his experience and insight into this process. We also adopted ideas from the focused crawls run by Klein et al.
Each diagram below illustrates the crawling algorithm used to acquire a different Memento object. Hypercane’s input types are shown at the top.
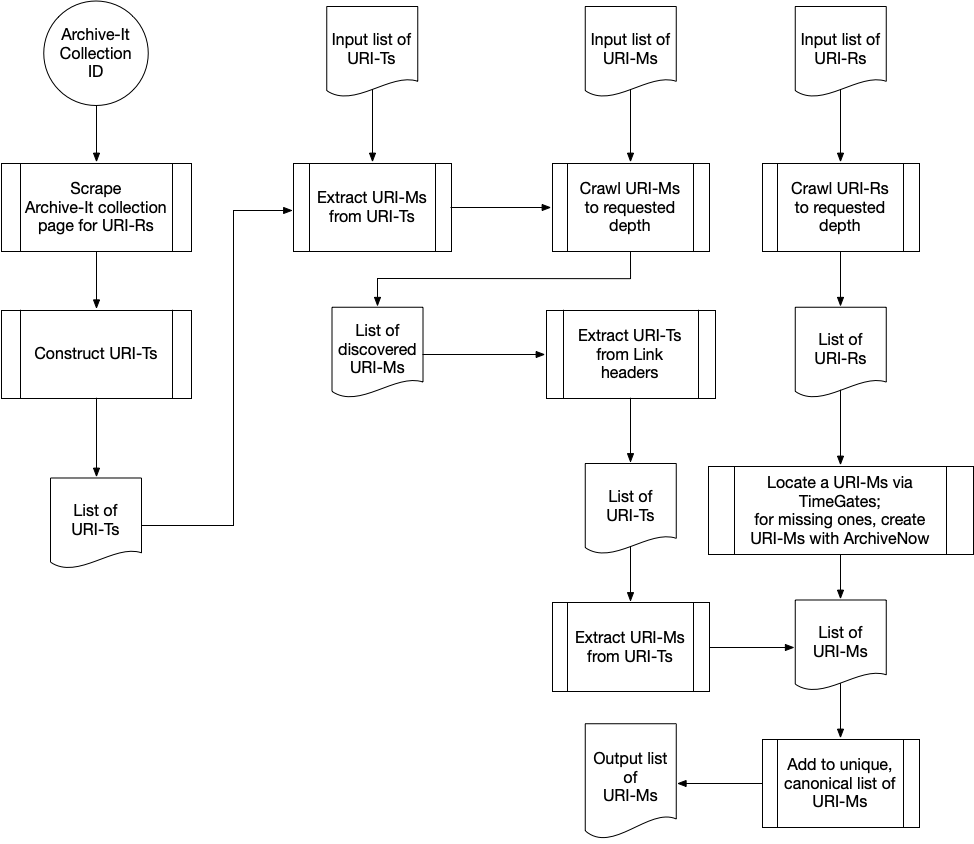
A flowchart demonstrating how Hypercane produces a list of URI-Ms from a crawl with one of the different input types shown at the top. This flowchart documents how hc identify mementos functions when we use the --crawl-depth argument.
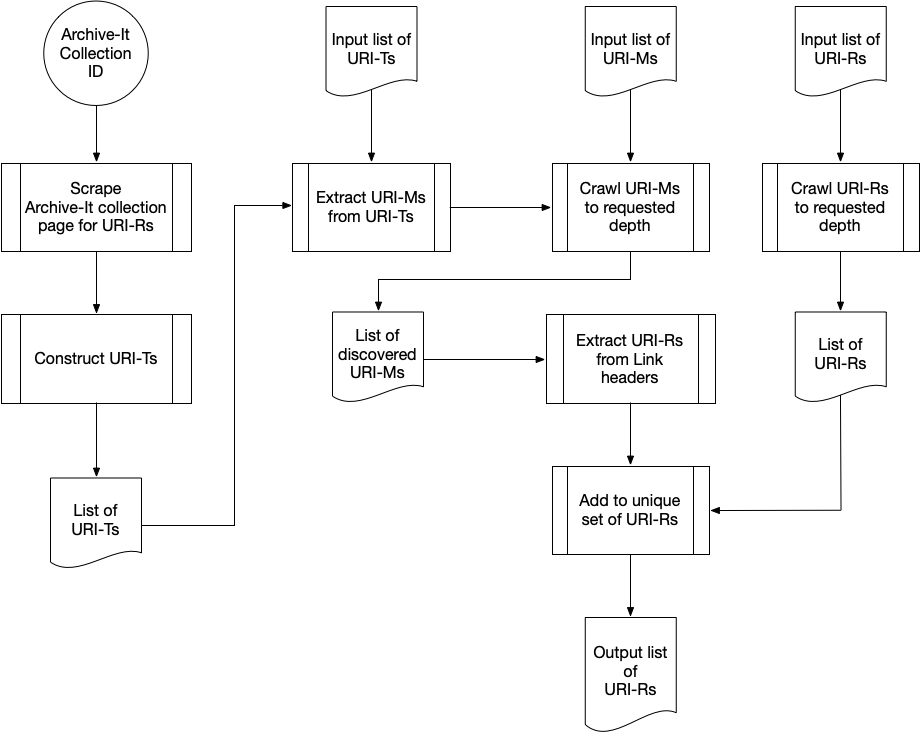
A flowchart demonstrating how Hypercane produces a list of URI-Rs from a crawl with one of the different input types shown at the top. This flowchart documents how hc identify original-resources functions when we use the --crawl-depth argument.
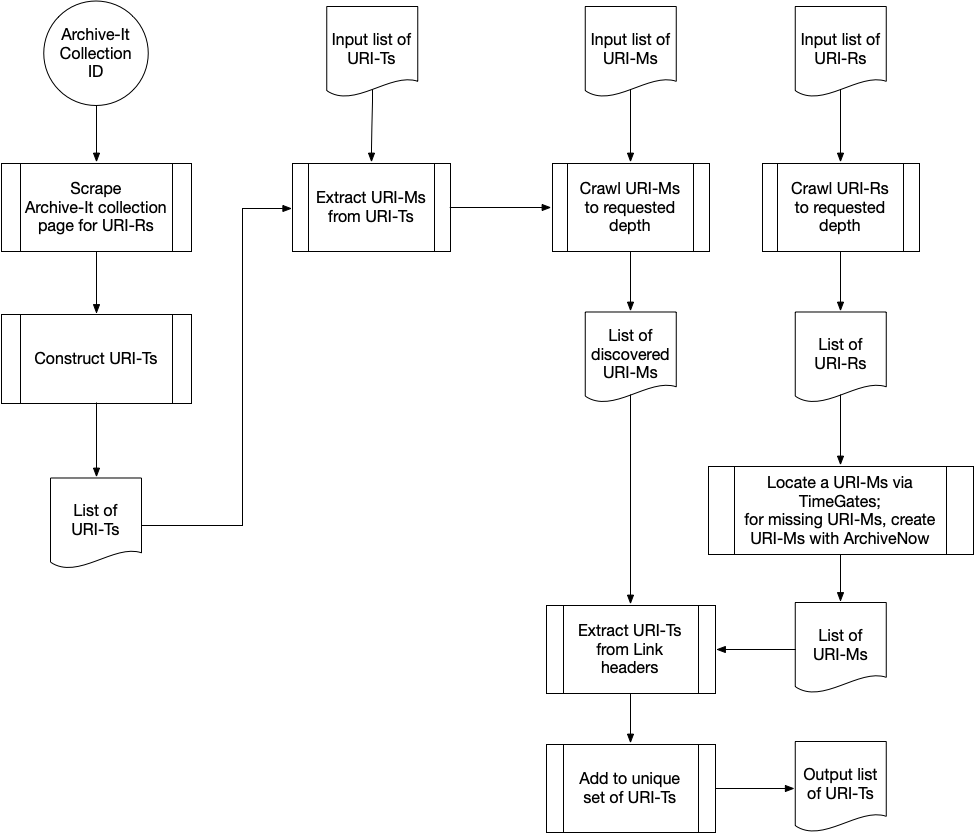
A flowchart demonstrating how Hypercane produces a list of URI-Ts from a crawl with one of the different input types shown at the top. This flowchart documents how hc identify timemaps functions when we use the --crawl-depth argument.
Note
Crawling is still being developed for trove, pandora-subject, and pandora-collection input types.